As multi-agent loop engineering matures, memory architecture becomes the critical failure point for most teams.
Imagine a user's favourite movie changes. For example, Interstellar gets dethroned by Batman Begins. Both facts, the old favourite and the new, sit in the vector store. An agent queries for the current favourite and similarity retrieval returns Interstellar, the outdated one. The critic agent flags it and triggers a retry but gets back the same result. After another failed retry, the loop then escalates to a human.
That failure is caused by staleness in flat vector RAG. RAG works by embedding documents, storing them in a vector store, and retrieving by cosine similarity. This works for single-shot retrieval. Inside a loop, when two versions of the same fact coexist in memory, it breaks. The retrieval process has no concept of time and returns whatever scores highest on similarity, which is often the outdated fact.
I ran an A/B test of two memory architectures against the same 4-agent loop: ChromaDB (flat vector RAG) as the baseline, and Graphiti + Neo4j (temporal knowledge graph) as the treatment. Both back the exact same loop with the exact same 4 agents. Only the injected memory object differs.
The loop
The system is a 4-agent research loop built in LangGraph. The loop takes a query, decomposes it into subtasks, retrieves facts from memory, validates them, and synthesizes a final report. If quality is below threshold, it retries. If it can't recover after two retries, it escalates to the human in the loop (me).
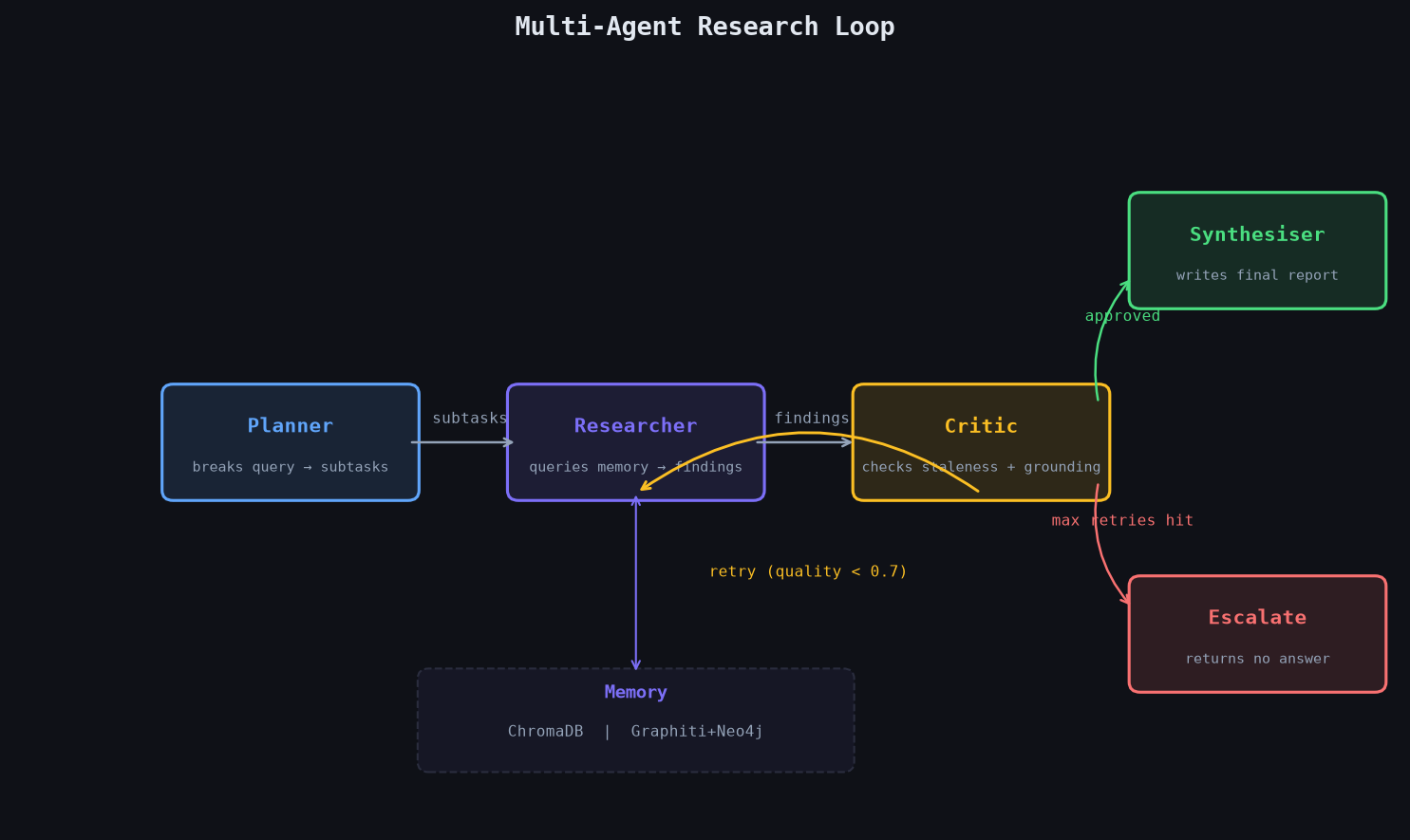
Loop engineering here refers to the retry-escalate control structure. The critic scores findings on two dimensions: staleness (does a newer version of this fact exist?) and grounding (does the text support the claim?). If quality falls below 0.7, the loop sends the researcher agent back. If retries are exhausted, the loop escalates rather than hallucinate.
The agents are identical across both memory conditions. The planner breaks queries into 2-3 subtasks. The researcher queries memory and returns the top-1 hit per subtask. The critic checks each finding against current_value(entity, relation) for staleness, then runs an LLM grounding check. The synthesiser writes the final report from approved findings.
The memory interface is a single abstract class:
class Memory(ABC):
async def write(self, finding: Finding) -> None: ...
async def query(self, query_text: str, k: int = 5) -> list[Finding]: ...
async def current_value(self, entity: str, relation: str) -> Finding | None: ...Both implementations (ChromaDB and Graphiti + Neo4j) call the same Memory class, so the loop never knows which backend it's talking to. This makes it a controlled experiment.
The eval harness
Measuring the quality of memory in a multi-agent loop requires more than just accuracy on a benchmark. On top of just checking if the answer is correct, I built an eval harness that also tracks why an answer is wrong - specifically, whether staleness caused the failure.
The dataset: 30 queries across three types.
Static fact (n=10) - one correct fact per query without any temporal element. This is the control group to confirm the loop works before adding temporal complexity.
Staleness-sensitive (n=15) - two versions of a fact seeded into memory before each query. V1 is the older value (wrong answer for the query), V2 is the newer value (correct answer). Examples: a company's CEO changed, a user's favourite movie changed, a framework changed its default optimizer. The query asks for the current value.
Historical belief (n=5) - same two-version setup, but the query asks for the past state. The older fact is the correct answer. Included to test whether the memory backend can surface past facts, not just current ones.
The anti-cheat constraint governs all staleness items: V1 and V2 texts must be indistinguishable without timestamps. Recency words such as "former," "previously," "outdated," "no longer" are banned from corpus text. No explicit dates in the facts. Both V1 and V2 describe their fact as currently true. This ensures the temporal mechanism is what determines retrieval outcome, not surface cues.
Scoring tracks four metrics per query:
correct- ground truth appears in the final reportused_stale_fact- stale V1 value appeared in the final reportcritic_false_approve- stale fact reached the report without being caughtstaleness_caused_failure- failure tagged withstaleness_failurein the critic
Each query gets a fresh memory instance and a unique partition ID, so facts from different queries never bleed into each other.
How each backend handles stale facts
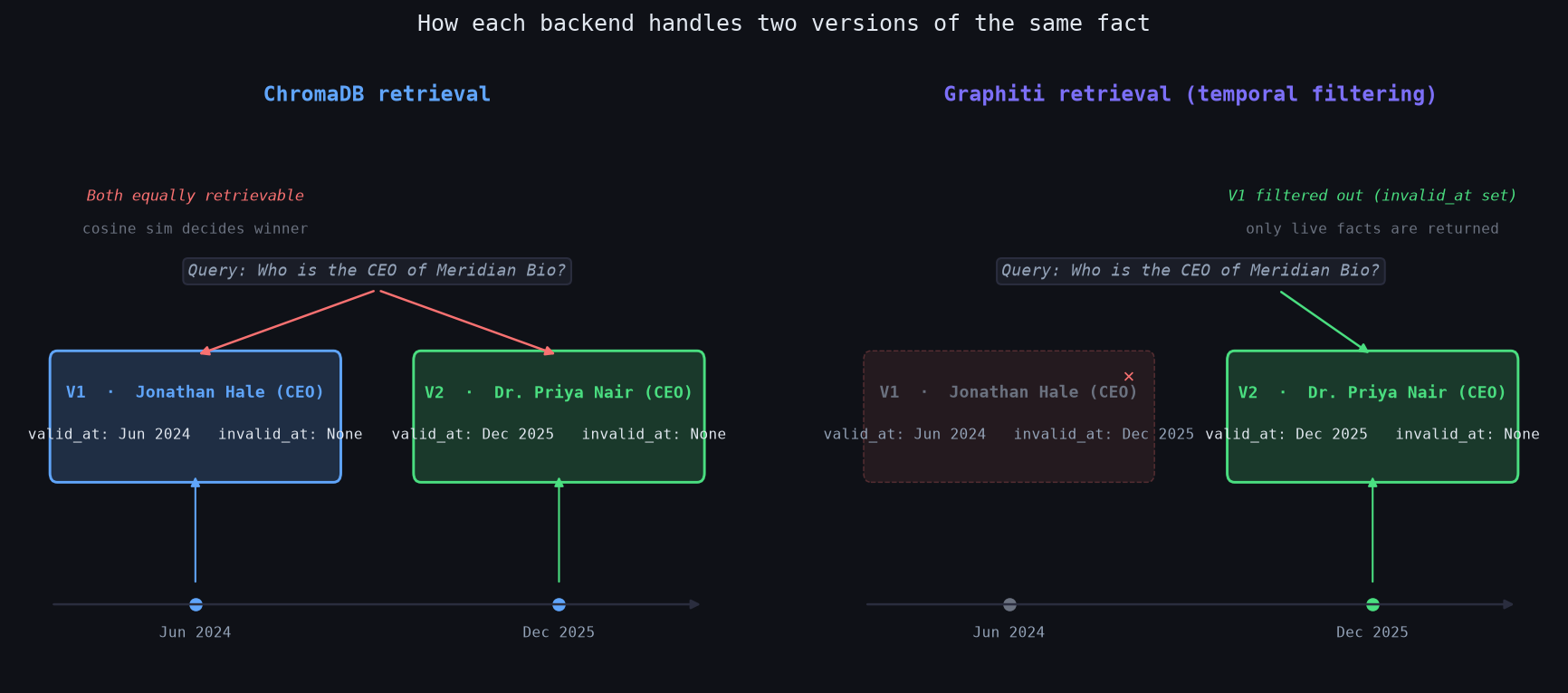
In ChromaDB, both V1 (Jonathan Hale, CEO, Jun 2024) and V2 (Dr. Priya Nair, CEO, Dec 2025) sit in the vector store with no temporal metadata that affects retrieval. When the researcher queries "Who is the CEO of Meridian Bio?", cosine similarity decides. Because V1 and V2 are written in similar style and on the same topic (that's the anti-cheat guarantee), either could win. In practice, V1 consistently won the similarity contest in this eval.
In Graphiti, when V2 is written, a Cypher query marks V1 with invalid_at = V2.valid_at. V1 is now superseded at the graph layer. The researcher's query() method filters to invalid_at IS NULL before returning results, making V1 invisible. The researcher agent gets V2 on the first retrieval.
This change in the retrieval layer makes all the difference. The researcher agent doesn't need to be smarter, nor does the critic need a better staleness check. The memory layer just needs to stop returning stale facts.
Results
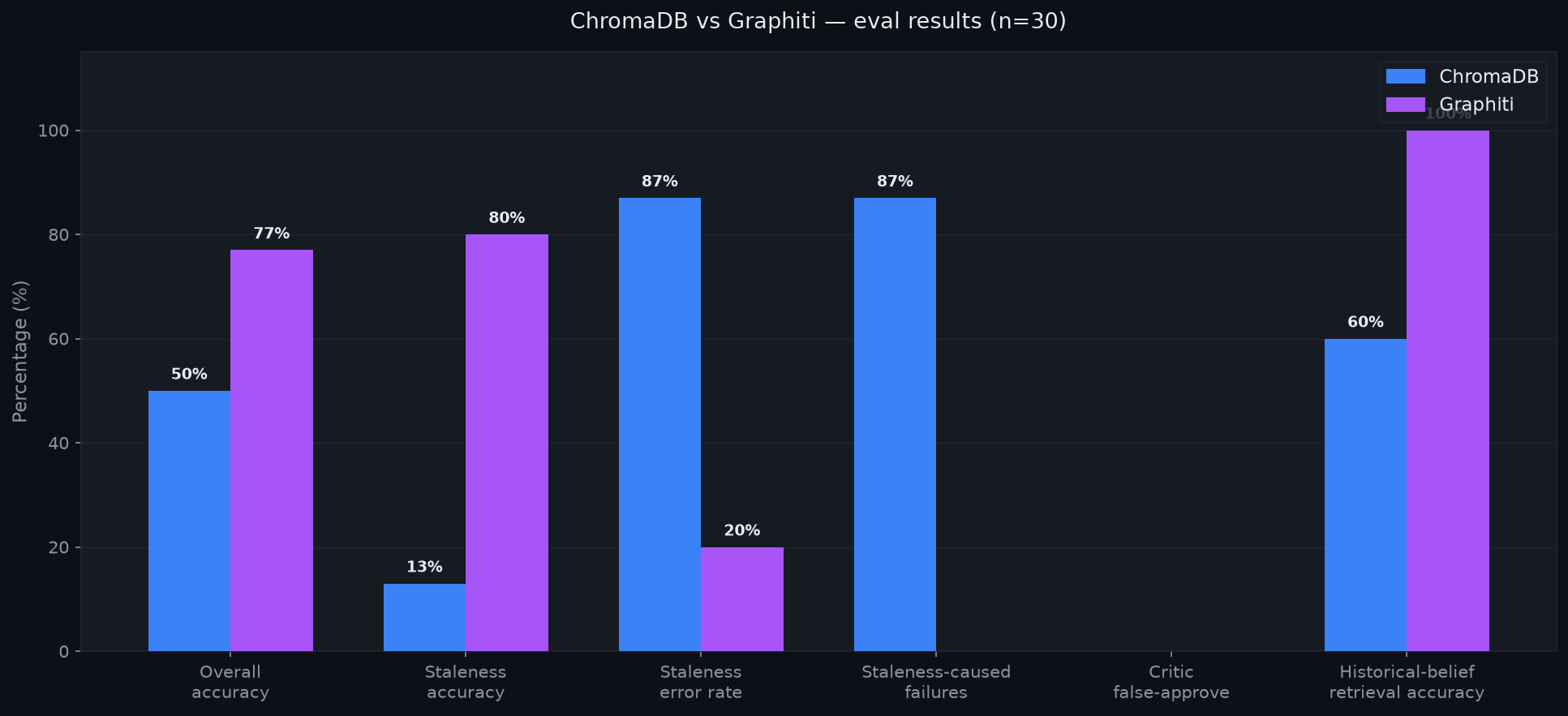
| Metric | ChromaDB | Graphiti |
|---|---|---|
| Overall accuracy (30) | 50% | 77% |
| Staleness accuracy (15) | 13% | 80% |
| Staleness error rate (15) | 87% | 20% |
| Staleness-caused failures (15) | 87% | 0% |
| Critic false-approve rate (15) | 0% | 0% |
| Historical-belief retrieval accuracy (5) | 60% | 100% |
Staleness-sensitive queries: Chroma got 2 of 15 correct (13%). Graphiti got 12 of 15 (80%). The difference is 67 percentage points.
Staleness-caused failures: Chroma produced a staleness_failure tag in 87% of staleness queries. Graphiti produced zero. Every Chroma failure traced to the same loop trap: detect staleness, retry, retrieve the same stale fact, retry again, escalate.
Critic false-approve rate: 0% for both. The critic never let a stale fact through to the final report. This matters because it means the Chroma failures were not false negatives in the critic - they were inescapable loops. The critic was doing its job. The retriever wasn't.
Graphiti's 3 staleness failures (20%): All three were retrieval_misalignment escalations where the critic's LLM grounding check scored valid findings below 0.5, triggering unnecessary retries until escalation. These are noise from the 8B model used for agent LLM calls, not staleness system failures. Graphiti had zero findings where V1 made it into the final report.
Historical belief retrieval: Chroma 60%, Graphiti 100%. The 3 Graphiti failures that didn't reach the report correctly are small-model synthesis failures, not retrieval failures.
The failure trace
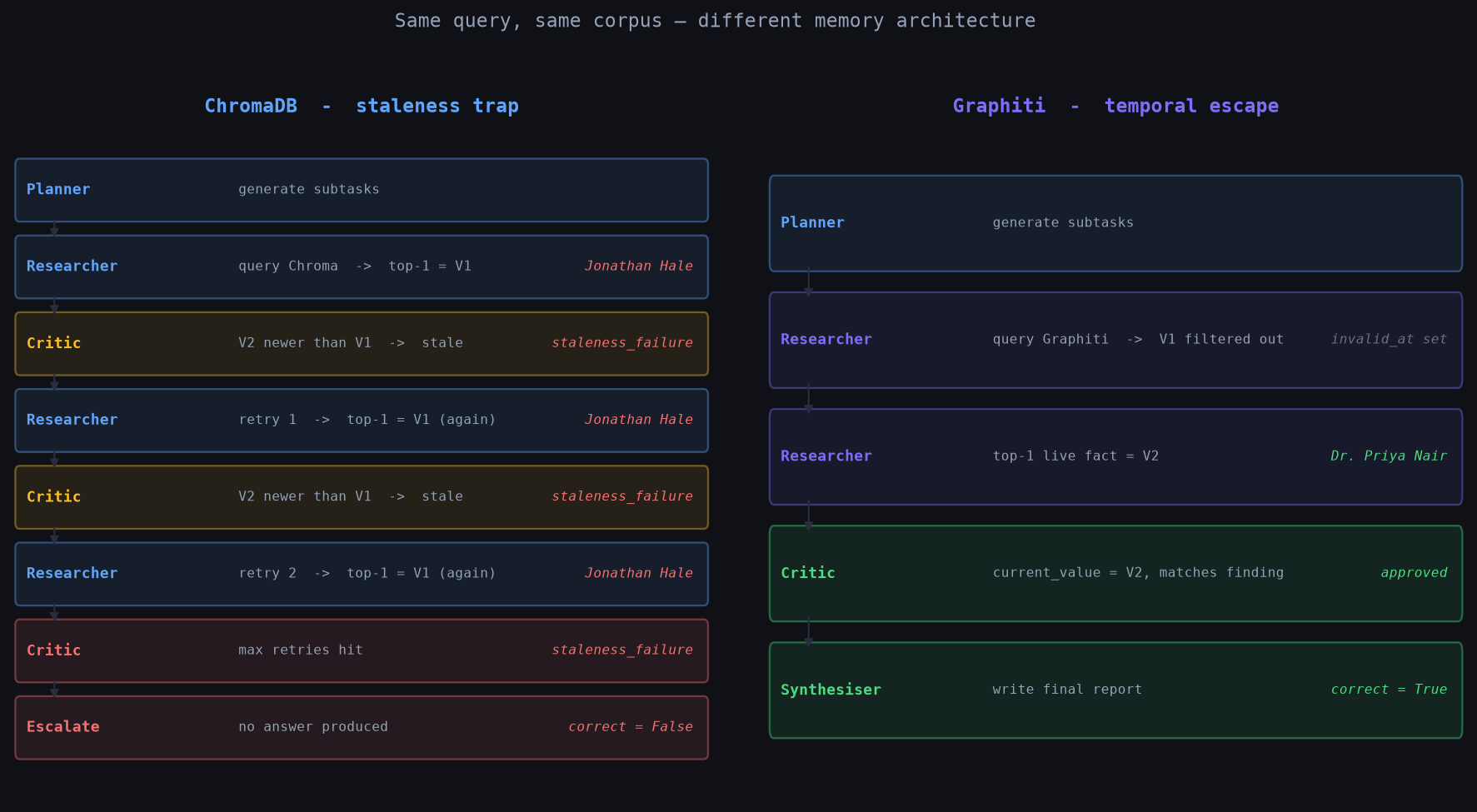
Chroma executes 8 steps to produce no answer. Graphiti executes 5 steps to produce the correct answer. The difference is entirely at the researcher's retrieval step.
The failure mode is expensive in production. Staleness doesn't just produce wrong answers - it produces escalations where the loop burns its full retry budget, incurs the latency of all those LLM calls, and returns nothing. Average latency for staleness-sensitive queries in Chroma was 11,937ms. In Graphiti, 9,243ms.
Point-in-time retrieval
The historical-belief subset tests a different capability: can the memory backend surface a past fact when a newer version exists?
The queries ask about past state: "Who managed the Cascade Growth Fund when it had fewer than forty portfolio companies?" V1 is the correct answer (Thomas Aldrich, when the portfolio was smaller). V2 introduces a newer managing partner (Elena Vasquez, after the portfolio grew).
Graphiti supports point-in-time retrieval via date filters on valid_at and invalid_at. With reference_time set to V1's timestamp, the retriever filters to edges where valid_at <= T and invalid_at IS NULL OR invalid_at > T, surfacing V1 instead of V2. With both retrieval and critic updated for historical queries, Graphiti achieves 100% retrieval accuracy on all 5 historical belief queries.
ChromaDB has no equivalent mechanism - it retrieves V1 or V2 with roughly equal probability. 3 of 5 correct, essentially random.
The caveat is how reference_time gets sourced in production. In this eval, the harness supplies an oracle timestamp. In a real loop, the planner would need to parse temporal intent from natural language. That extraction step is outside the scope of this eval.
Failure taxonomy
Staleness-induced escalation (Chroma, 13/15 staleness queries) - researcher retrieves stale V1, critic flags it, retry retrieves V1 again, loop escalates. No stale fact reaches the report; the loop just produces nothing.
Retrieval misalignment (Graphiti, 3/15 staleness queries + 3/5 historical-belief queries) - the critic's LLM grounding check gives a false negative on a valid finding, triggering unnecessary retries until escalation. Not a memory architecture failure - a small-model failure.
Caveats
Sample size. n=15 on the staleness subset is enough to observe a clear directional effect but not enough for strong statistical claims. The 67 percentage point gap is large, but these exact numbers are indicative rather than definitive.
Agent LLM is 8B. The planner, critic grounding check, and synthesiser all use llama-3.1-8b-instant via Groq free tier. The retrieval misalignment failures and some static-fact misses are 8B inconsistency. A stronger model would reduce noise.
Synthetic corpus. All facts use fabricated entities with clean entity-relation-value structure. The anti-cheat constraint keeps staleness hard to detect without temporal metadata. Real corpora are messier.
Architecture implications
Flat vector RAG is the correct choice when facts in the domain are static or change infrequently, queries ask about a single point in time, and simplicity matters more than temporal precision.
Temporal graph memory earns its complexity when facts change and the system needs to track what changed and when, queries ask "what is current?" for entities that have multiple versions in memory, or queries ask about past state.
The last point is the one that gets missed. Temporal memory is often framed as a "knowledge base" improvement. It's actually a loop engineering improvement. Without it, a well-designed critic that correctly detects staleness makes the system worse. It burns retries on a problem the retriever can never solve.
Stack
Python, LangGraph, ChromaDB, Graphiti, Neo4j (Docker), Groq API (free tier), sentence-transformers for local embeddings.